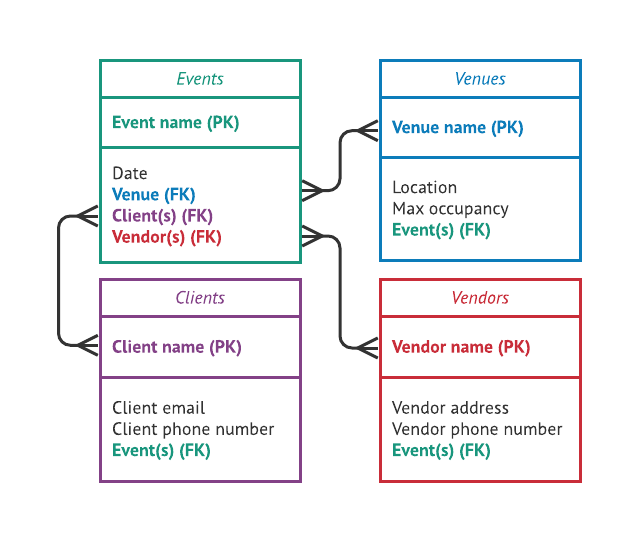
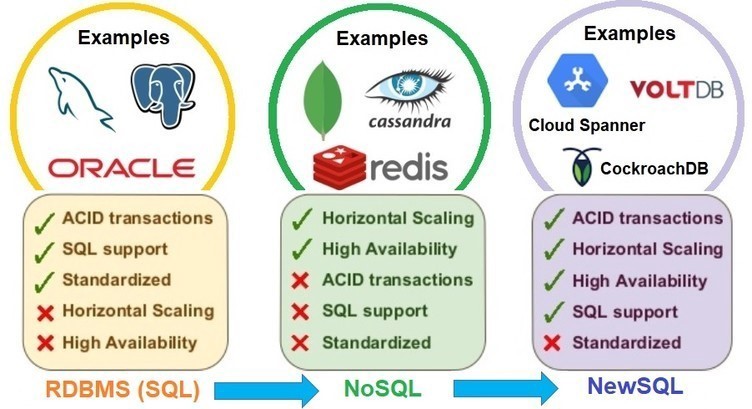
A data hub is a centralized platform or repository where data from various sources within an organization or across multiple organizations is collected, stored, managed, and shared. It serves as a central point for data integration, allowing different systems and applications to access and utilize the data for various purposes such as analytics, reporting, and decision-making.
Data hubs typically employ technologies such as data warehouses, data lakes, or data virtualization to aggregate and manage data. They may also incorporate data governance and data quality processes to ensure that the data is accurate, consistent, and secure.
The primary goals of a data hub include improving data accessibility, facilitating data collaboration and sharing, and enabling organizations to derive valuable insights from their data assets.
Let’s delve deeper into the differences between Data Hubs, Data Warehouses, and Data Lakes:

Data Hub:
- A data hub is a centralized platform for collecting, storing, managing, and sharing data from various sources within an organization or across multiple organizations.
- It focuses on data integration, enabling different systems and applications to access and utilize the data.
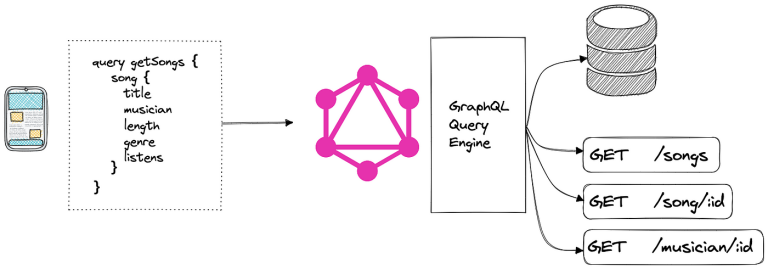
- Data hubs often incorporate technologies such as data virtualization to provide a unified view of data without physically moving or replicating it.
- Data hubs can serve as a foundation for data governance, data quality management, and data sharing initiatives within an organization.
Data Warehouse:
- A data warehouse is a centralized repository that stores structured data from various sources for reporting and analysis purposes.
- It is designed for querying and analysis, typically using SQL-based tools and techniques.
- Data warehouses are optimized for read-heavy workloads and are structured to support analytical queries efficiently.
- They often undergo an Extract, Transform, Load (ETL) process to integrate data from disparate sources and transform it into a consistent format suitable for analysis.
Data Lake:
- A data lake is a centralized repository that stores large volumes of raw, unstructured, semi-structured, or structured data at scale.
- Unlike data warehouses, data lakes can store data in its native format without requiring upfront schema definition.
- Data lakes are designed to store diverse types of data, including structured data from databases, semi-structured data like JSON or XML, and unstructured data like images or text documents.
- They provide flexibility for data exploration and experimentation, allowing data scientists and analysts to explore data without predefined schemas.
- Data lakes may utilize technologies such as Apache Hadoop or cloud-based storage solutions like Amazon S3 or Azure Data Lake Storage.
While data hubs, data warehouses, and data lakes are all centralized repositories for data, they serve different purposes and are designed to handle different types of data and workloads. Data hubs focus on data integration and sharing, data warehouses are optimized for analytical querying, and data lakes provide flexibility for storing and analyzing diverse types of data at scale.
The Deeper into each concept:
Data Hub:
- Data Integration: A data hub primarily focuses on integrating data from various sources, including databases, applications, and external systems. It provides a unified view of the data, allowing different systems and applications to access and utilize it seamlessly.
- Data Sharing and Collaboration: Data hubs facilitate data sharing and collaboration within organizations or across business ecosystems. They enable different departments or business units to access and share data securely, promoting collaboration and informed decision-making.
- Data Governance and Quality: Data hubs often incorporate data governance and data quality management processes to ensure that the data is accurate, consistent, and compliant with regulatory requirements. They establish policies, procedures, and standards for data management and enforce them across the organization.
- Real-time Data Access: Some data hubs are designed to provide real-time or near-real-time access to data, allowing organizations to make timely decisions based on the latest information available.
- Scalability and Flexibility: Data hubs are designed to be scalable and flexible, capable of handling growing volumes of data and evolving business requirements. They can adapt to changes in data sources, formats, and usage patterns over time.
Data Warehouse:
- Structured Data Storage: Data warehouses primarily store structured data from transactional systems, operational databases, and other structured data sources. They are optimized for storing and querying structured data in a relational format.
- Analytical Querying: Data warehouses are designed for analytical querying and reporting, supporting complex SQL-based queries for data analysis, business intelligence, and decision support.
- ETL Processing: Data warehouses often undergo an Extract, Transform, Load (ETL) process to integrate data from disparate sources, transform it into a consistent format, and load it into the warehouse for analysis.
- Performance and Optimization: Data warehouses are optimized for read-heavy workloads, with features such as indexing, partitioning, and query optimization to improve query performance and response times.
- Historical Analysis: Data warehouses maintain historical data over time, allowing organizations to perform trend analysis, historical reporting, and forecasting based on historical data.
Data Lake:
- Raw Data Storage: Data lakes store raw, unstructured, semi-structured, or structured data in its native format without requiring upfront schema definition. They can store diverse types of data, including text, images, videos, log files, sensor data, and more.
- Schema-on-Read: Unlike data warehouses, which enforce a schema-on-write approach, data lakes follow a schema-on-read approach, allowing users to apply schema and structure to the data when it’s accessed or analyzed.
- Data Exploration and Experimentation: Data lakes provide flexibility for data exploration and experimentation, enabling data scientists, analysts, and other users to explore and analyze data without predefined schemas or use cases.
- Big Data Processing: Data lakes are often used for big data processing and analytics, leveraging technologies such as Apache Hadoop, Apache Spark, or cloud-based platforms like Amazon EMR or Google Dataproc for distributed data processing.
- Cost-effective Storage: Data lakes leverage scalable and cost-effective storage solutions, such as cloud object storage (e.g., Amazon S3, Azure Data Lake Storage), to store large volumes of data at a lower cost compared to traditional storage systems.
In summary, while data hubs, data warehouses, and data lakes are all centralized repositories for data, they serve different purposes, handle different types of data, and are optimized for different use cases and workloads within an organization.